DARTS : https://arxiv.org/abs/1806.09055
본 포스팅은 “DARTS: Differentiable Arhcitecture Search”에 관한 내용을 정리하였다. DARTS는 생각의 전환점(Non-diiferentiable → Differentiable)을 통해 획기적이고 효율적인 방법을 제시한 논문이다. 언제나 하나의 전환점을 통해 새로운 논문이 게재되고, 이를 기반으로 많은 연구자들이 발전하고 성장할 수 있는 것 같다.
Introduction
최근 NAS (Network Architecture Search) 분야에서 NAS [1], NASNet [2], ENAS [3]와 같은 논문들이 좋은 성능을 보여주었으나, 상당히 많은 GPU가 요구된다는 단점이 있다. 또한 기존에는 discrete search space에서는 candidate architecture를 searching 하기 위해서는 많은 양의 평가가 필요하다. 이러한 문제를 해결하기 위해 DARTS의 저자들은 search space를 continuous relaxation을 통해 미분이 가능하도록 만들고, validation performance에 대한 gradient descent 기반의 학습 방식을 통해 보다 빠르고 높은 성능을 보여준다.
Search Space
Cell을 search하는 방식으로 진행되며, Cell은 N개의 노드로 구성된 DAG(Directed Acyclic Graph) 구조이다. 각 노드들은 latent representation이고 노드들을 연결하는 connection들은 operation이다.
Continuous Relaxation and Optimization
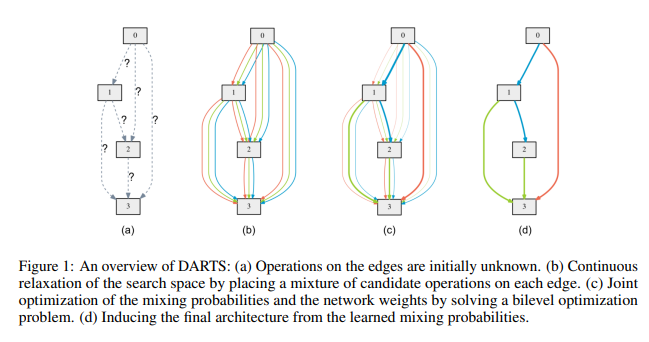
Continous Relaxation의 의미 : Search space를 continous 하게 만들기 위해서, categorical choice가 가능한 모든 operation에 대한 softmax값(각 operation에 대한 확률 값)을 각 operation의 가중치로 활용한다. (Figure 1의 (b) 참고, 각 operation에 대한 가중치를 곱해서 더해주는 방식!)
*기존의 NAS 방식들은 각 operation에서의 확률 값 중 max 값을 가지는 operation으로 child network를 만들었음. 각 operation에 대한 모든 경우의 수를 접근하다보니 너무 많은 양이여서 비효율적임.
각 단계에 대해서 살펴보자면,
1. Figure 1의 (a)와 같이 총 4개(0, 1, 2, 3)의 노드를 가진 DAG의 구조가 있다. 아직 각 node들을 연결하는 operation은 무엇인지 정해지지 않은 상태이다.
2. Figure 1의 (b)와 같이 각 노드에 mixed operation(Continuous relaxation을 통해 각 operation들이 가중치를 곱해서 더해지는 형태, 쉽게 말해 weighted sum)을 적용한다.
3. Figure 1의 (c)와 같이 학습이 진행됨에 따라 높은 가중치를 가지는 일부 operation들이 선택되어진다.
4. Figure 1의 (d)와 같이 높은 가중치를 가진 operation들이 선택되며, 최종적인 architecture가 생성된다.
Mixed operation을 식으로 표현하면 다음과 같다.
$$ \bar {o}^{(i, j)}(x)=\sum_{o\in O}\frac {exp({\alpha_o}^{(i, j)})}{\sum_{o'\in O} exp({\alpha_{o'}}^{(i, j)})}o(x) $$
여기서 $O$는 모든 operation(convolution, max pooling, $zero$ 등)들의 집합이고, $x$는 node의 값(ex. $x^{(i)}$는 $i$번째 노드의 값), $\bar o^{(i, j)}$는 노드 $i$와 노드 $j$ 사이의 mixed operation을 나타내며, $\alpha _o ^{(i,j)}$는 노드 $i$와 노드 $j$ 사이의 operation $o$에 대한 가중치를 나타낸다.
operation $o$에 대한 가중치에 대한 softmax 함수를 취하고, softmax를 통해 나온 값을 $o(x)$에 곱한 후, 이 과정을 모든 $o$에 대해 수행하고 더하면 최종적인 mixed operation 값을 구할 수 있다. Search가 끝날 때, discrete architcture는 각각의 mixed operation을 가장 가능성이 높은 연산인 $o^{(i, j)} = argmax_{o \in O}\alpha_o^{(i, j)}$를 얻게 된다. 즉, 구조를 최적화(architecture search)함에 있어 최적의 $\alpha = \{\alpha^{(i, j)}\}$의 집합을 찾는 문제로 볼 수 있다.
학습이 진행될 때, $\alpha$(각 operation에 대한 가중치) 뿐만 아니라 $w$(모든 연산들의 weights(ex. convolution filter의 weights)) 또한 최적화가 필요하며, 이 두 가지 값이 validation loss인 $L_{val}$과 train loss인 $L_{train}$에 반영되게 된다. Architecture search의 목표는 $L_{val}$을 최소화하는 것이며, 이는 $L_{val}(w^*,\alpha^*)$를 최소화하는 $\alpha^*$를 찾는 것으로 볼 수 있다. 참고로, 여기서 $w^*$는 training set에 대해 최적화가 되어 있어야 한다. 이를 식으로 나타내면 다음과 같다.
$$ \min_{\alpha}{} \ L_{val}(w^*(\alpha),\alpha) $$
$$ \mathbf{s.t.} \ w^*(\alpha) = argmin{}_w \ L_{train}(w,\alpha) $$
학습 시에 $w$가 $w^*$(최적의 값)가 될 때까지 학습한 후 $\alpha$를 1 step 학습하는 것은 너무 많은 시간이 소요된다. 그래서 DARTS의 논문에서는 $w$를 1-step만 gradient update 하고 $\alpha$를 1 step 학습하는 방식을 제안, 즉 $w$를 근사하여 사용하자고 제안한다. 이는 아래 Approximate Architecture Gradeint에서 확인해보자.
$$ \nabla_\alpha L_{val} (w^{\ast} (\alpha),\alpha) \\ \approx \nabla_\alpha L_{val} (w-\xi \nabla_w L_{train}(w, \alpha), \alpha) $$
우선 앞서 말한 것과 같이 $w$를 최적의 값인 $w^*$를 찾는 과정은 비효율적이므로 위의 식과 같이 $w^*$를 근사하여 사용한다. → 관련된 수식은 [4]를 통해서 공부하는 것을 추천한다(조금 더 공부하고 추가할 수 있도록 하겠습니다)! (만약 $w$가 local optimum 상태라면, $\nabla_w L_{train}(w, \alpha) = 0$이 되어서 위의 식은 $\nabla_\alpha L_{val}(w, \alpha)$로 감소할 것임!) 이를 바탕으로 Algorithm 1과 같은 과정을 통해 학습을 수행하게 된다.

Algorithm에서의 $\xi$(gradient update시의 learning rate)의 값이 변화함에 따라 $\alpha$와 $w$의 수렴도를 볼 수 있다. 그림에서 빨간색 점선 부분은 local optimum이고 빨간색 동그라미 부분이 global optimum이다. $\xi$를 사용하였을 때 global optimum영역과 근사하게 수렴하였으며, 적절한 값을 설정하였을 때 global optimum에 도달할 수 있다.
First-order Approximation
DARTS 논문에서는 $\xi=0$인 경우를 first-order approximation이라 표현하고, $\xi > 0$인 경우를 second-order approximation이라고 표현한다. $\xi=0$일 때, $w^*(\alpha)=w$가 되며 이는 $\alpha$를 업데이트시에 $w$가 최적의 값이라고 가정하며, approximation 과정을 수행하지 않는다. 이는 속도면에서는 빠를 수 있으나, 성능면에서는 저하가 있는 trade-off 관계이므로 상황에 맞게 사용하면 될 것 같다!
Deriving Discrete Architecture
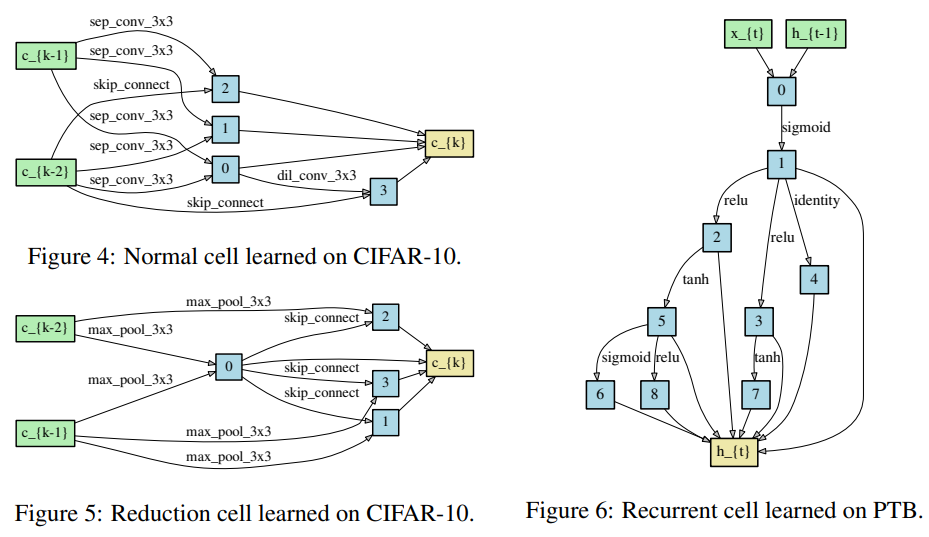
최종적으로 Discrete architecture를 만드는 단계로서, 각 nodes들로부터 얻은 operations들 사이에서 $top-k$개의 큰 strength를 가진 operation만 남기게 되는 과정이다(Figure 1의 (d) 참조). DARTS의 논문에서는 convolutional cell에서는 $k=2$, recurrent cell에서는 $k=1$로 설정하였으며 이는 위의 그림에서 확인할 수 있다.
Reference
[0] https://arxiv.org/abs/1806.09055
[1] https://arxiv.org/abs/1611.01578